[6.824系列] Outline of lab1 solution
本文主要总结了如何实现6.824 lab1的大纲, 方便自己和读者能够迅速理解MapReduce具体要实现些什么.
概览
首先整个MapReduce的过程可以参考下图, 分为两个阶段: Map和Reduce阶段.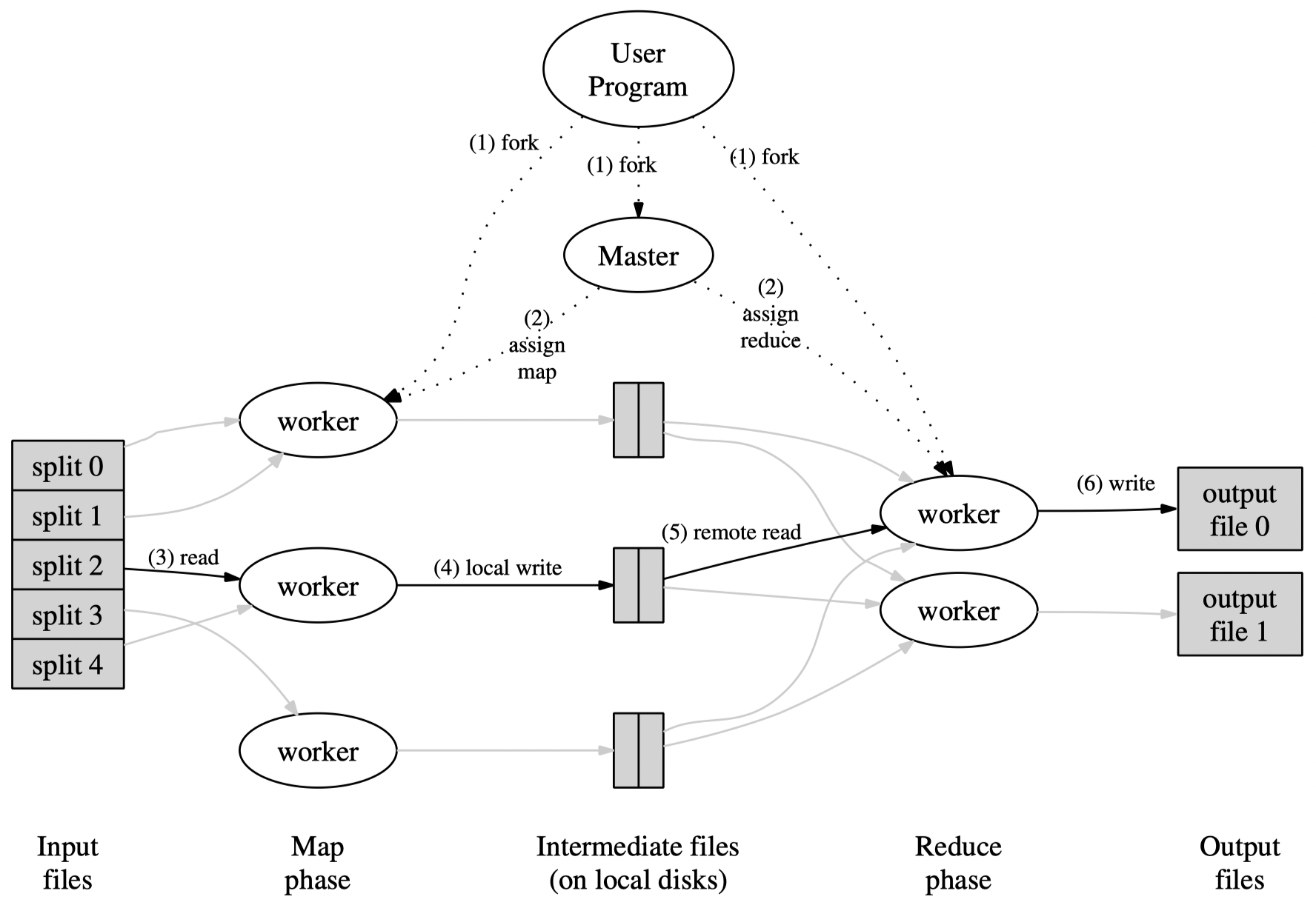
从这个图中我们可以总结出MapReduce整体的工作流程如下
- 将任务的输入文件拆分多个split文件
- 创建多个Map任务, 每个任务对应输入若干个split
- 在多个worker服务器上执行Map任务, 并将输出写入到Intermediate files中
- 当所有Map完成后, MapReduce进入Reduce阶段, 为多个worker服务器分配Reduce任务
- 每个Reduce任务读取对应的Intermediate files完成Reduce任务, 并将输出写入对应的output files
问题
Q1: 什么时候由谁来对任务输入文件进行split? 如何split?
A: 由Master在MapReduce任务初始化的过程完成, split的目的是为了将一个任务拆分成多个子任务给到多个worker机器运行, 实现并发加速, 因此split文件的数量应该等同于worker机器数量来设置. 同时split应该按照预设好的文件的大小来进行划分(比如一个split文件为1KB大小).
Q2: Map是什么?
A: 接收一个key/value的pair, 产生一系列的key/value中间结果的过程就是Map, 比如说下面是一个wordcount的map例> 子
2
3
4
5
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
Q3: Reduce怎么知道自己对应的是哪些Intermediate files?
A: 我们把对Map产生的每一个key/value, 对key进行hash后分配到一个Reduce任务, 具体来说:
- 给定一个Map任务X以及产生的key/value pair
- Reduce Y = hash(key) % nReduce
- write to “mr-X-Y” file
因此, 对于给定的Reduce任务Y, 它去读取所有的mr-?-Y文件作为输入.
Q4: 如何处理Map任务或者Reduce任务执行超时或失败的问题
A: 利用超时机制和Master被动分配任务来实现超时重试, 对每一个任务都记录其开始的时间, 当worker请求分配任务的时候, 遍历所有的任务判断是否超时, 如果超时则是一个可以被分配的任务.
实现大纲
大纲可以分为两个部分: Master和Worker
1. Worker
对于每一个Worker, 它的执行过程都可以概括为:无限循环请求任务分配并执行直至MapReduce全部任务完成. 过程如下:
- 向Master申请分配任务(由Master决定分配Map还是Reduce任务)
- 如果Master返回MapReduce已经全部完成则退出循环
- 根据返回的任务类型(Map or Reduce)执行对应的处理过程
- 重复上述
1.1 Map处理
Map的输入: taskId(任务ID), nReduce(预设的Reduce个数), fileName(输入文件的访问路径)
这里需要注意fileName的定义, 在这个作业当中, 我们可以直接使用文件名作为fileName, 这是因为程序跑在单机环境下, 通过多个进程的形式模拟分布式环境, 因此默认情况下相关文件都存放在主程序的当前目录下, 因此可以通过文件名即可以访问到, 但是在生产环境, 我们往往会依托一个分布式文件系统来存放这些文件(比如GFS), 因此此时fileName应该是一个文件访问URL, 可以通过URL去分布式文件系统读取到对应文件.
Map的过程
- 读取文件内容并经map函数处理得到对应kv对集合
kva - 创建nReduce个临时文件
- 将
kva按照key hash值写入到对应临时文件 - 重命名临时文件为
mr-X-Y, X为taskId(mapId), Y为reduceId. - 通知Master, 该任务完成
这里采用约定大于配置思想, 因此不需要通知Master该任务输出文件的文件名, 但是如果是分布式文件系统的话需要给出系统接口返回的文件URL给Master.
1.2 Reduce处理
过程和Map处理类似
Reduce的输入: taskId, intermediateFileNames(中间文件访问路径的集合)
Reduce的过程
- 遍历读取中间文件, 并保存到一个内存的列表中
- 按照key来排序列表
- 将列表中每一个key和对应的value集合交给reduce函数处理
- 结果写入到临时文件并重命名
- 通知Master任务完成
2. Master
Master作为MapReduce的协调者, 需要对所有Map、Reduce任务的状态进行管理, 同时在对应的状态下进行任务分配. 总的来说需要具备以下功能:
- 任务初始化
- 任务分配
- 任务完成处理
2.1 任务初始化
这一过程实际上也是Master的初始化过程. 这一过程, Master需要设定好需要多少个Reduce和Map, 同时对相应的Map和Reduce任务进行初始化, 同时进入整个MapReduce进入Mapping状态.
2.2 任务分配
这个过程核心在于判断当前MapReduce(Master)处于什么状态从而分配相应的任务:
- 如果处于Mapping状态, 遍历MapTasks列表判断每一个任务是否可以被分配
- 判断该任务是否超时, 如果超时则需要将其状态修改为可被分配
- 如果处于Reducing状态, 遍历ReduceTasks列表进行类似的分配
- 如果处于Done状态, 则返回Exit状态码给worker告知整个MapReduce已经结束
2.3 任务完成处理
- 给定完成的任务ID: taskId
- 根据阶段Mapping/Reducing找到对应的Task
- 修改Task的状态为Finished
- 如果该阶段所有任务都已经完成,则推进Master的状态到下一阶段
[6.824系列] Outline of lab1 solution
http://zhiwei-feng.github.io/2022/04/10/outline-of-6-824-lab1-solution/